【事例】株式会社風音屋
当社監訳書籍『アジャイルデータモデリング - 組織にデータ分析を広めるためのテーブル設計ガイド』の寄稿事例をWEB掲載しています。
- 本書における寄稿事例の位置づけについては寄稿事例について を参照してください。
- 本ページに掲載している画像および図表については、いずれも同書籍からの引用となります。
株式会社風音屋
寄稿者:Analytics事業部 データエンジニア 妹尾拡樹
ウェブサービスのアクセスログに対してディメンショナルモデリングを適用する場合、どのようなテーブル設計にするのが良いでしょうか。本書の翻訳メンバーでディスカッションを行いました。
この寄稿を通して「データ分析者にとっての使いやすさ(ユーザビリティ)を意識すること」「初期フェーズでの過度なモデリングを避けること」「ユーザーのニーズに応じて段階的に設計を進化させること」「1人の思い込みではなく多様な意見を持つ人たちが集まって設計すること」など、アジャイルな姿勢こそがデータモデリングにおいて重要であることをお伝えします。
風音屋ではクライアント企業のデータ基盤を開発・運用しており、各案件でディメンショナルモデリングを実践しています。あるウェブサービスで「商品ページにアクセスしたユーザーをリストアップしたい」という相談がよせられました。ディメンショナルモデリングを採用する場合、どのようなテーブル設計にするのが良いでしょうか。本書の翻訳メンバー(風音屋の社員とアドバイザーたち)でディスカッションを行いました(図1)。

図1 翻訳メンバーによるディスカッション
ユーザー行動を扱うデータとしては、ウェブサーバ(例:Nginx)のアクセスログやアクセス解析ツール(例:Googleアナリティクス)のイベントログが存在します。これらのログはクリックや画面遷移のタイミングで生成されます。ログには「13時30分にこのIPアドレスから商品Aのページにアクセスした」といった詳細情報が含まれています。精緻なデータ分析を実現できる反面、データ量や項目の多さから「うまく使いこなせない」と悩むデータ分析者も多いのではないでしょうか。データエンジニアが「使いやすく加工されたテーブル」を用意することで、簡単にデータを活用できるようになります。
ディスカッションでは2つの設計方針があがりました(図2)。1つは「商品ページへのアクセス」に限定したファクトテーブル(fact_商品閲覧)を作る方針、もう1つは「全ページへのアクセス」を横断して1つのファクトテーブル(fact_サイトアクセス)で管理する方針です。
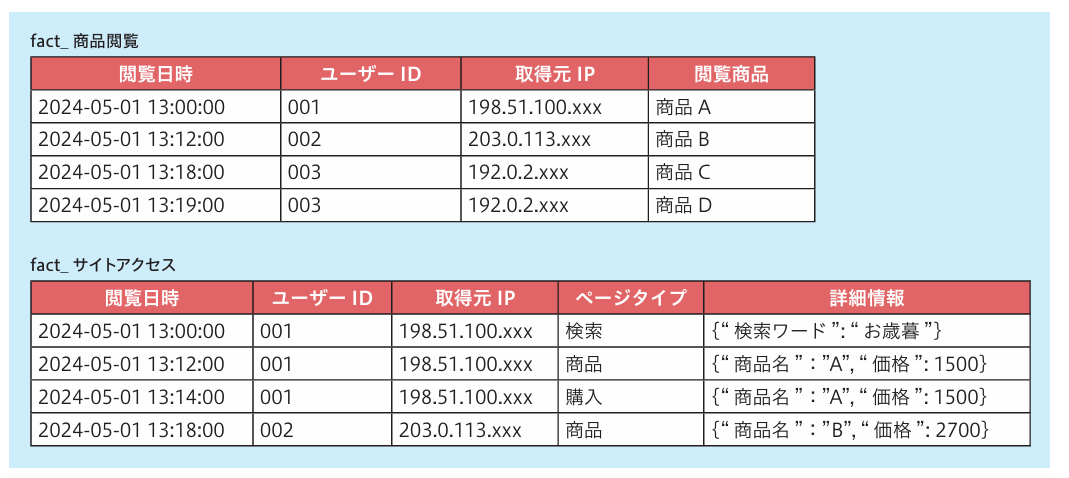
図2 ファクトテーブル設計の2つの案
「fact_商品閲覧」テーブルは「商品閲覧」を1つのビジネスイベントと捉えます。対象データを商品ページに絞っているため、必要最小限のカラムやレコードだけで済み、「データの使いやすさ」と「パフォーマンス」を両立できます。「商品ページにアクセスしたユーザーをリストアップしたい」という当面のゴールに対して、最短距離の設計をするならば、おそらくこの方針になるでしょう。
一方で、商品以外のページに関する分析や、複数のページを横断した分析を行う場合、「fact_商品閲覧」テーブルだけでは不十分です。「商品ページから購入ページへ遷移したユーザーのリストが欲しい」など、商品ページに閉じない要望が後から挙がるであろうことは容易に想像できます。「fact_商品閲覧」テーブルとは別に、ページごとに新しいファクトテーブルを作らなければならず、修正や管理のコストがかかってしまいます。
「fact_サイトアクセス」テーブルでは、商品ページや購入ページなど、各ページへのアクセスを汎用的に扱います。一度このテーブルを用意してしまえば、さまざまなデータ分析に活かせます。カラムやレコードは多くなってしまい、パフォーマンス観点では必ずしもベストではありませんが、利便性や保守性の高い選択肢です。
ディスカッションでは「fact_サイトアクセス」から始めるのが良いだろうという結論になりました(図3)。データ分析者の要望が変化しても柔軟に対応できるため、アジャイルに価値を創出しやすいからです。保有しているデータの量や種類が想定よりも少なければ、デメリットを無視できるかもしれません。もしデメリットが目立つようであれば、後から「fact_商品閲覧」テーブルに切り出すことも可能です。
ソフトウェア開発の世界には「早すぎる最適化は諸悪の根源」(ドナルド・クヌース)という格言があります。最初から過度に複雑なモデリングをするのは避け、状況に応じて軌道修正できるようにしておくのがスマートな設計だと考えました。
図3 ファクトテーブルの設計方針まとめ
ウェブサイトには異なる種類のページがあります。例えば、商品ページ、購入ページ、コンテンツページ、検索ページがあります。これを「ページタイプ」と呼ぶことにしましょう。アクセスログでは、ページタイプごとに異なる情報が保存されます。商品ID、コンテンツID、検索クエリといった情報です。本稿ではこれらを「ページ属性」と呼びます。システムによっては「ページ属性」をJSON形式などの半構造化データで1つのカラムに格納することがあります。先ほど挙げた図2の「fact_サイトアクセス」テーブルの「詳細情報」カラムではJSON形式の例を掲載しています。
ファクトテーブルを作る際には、JSON / STRUCT型などの半構造化データのままテーブルで管理するべきでしょうか。それともフラット化して別々のカラムで管理するべきでしょうか。「STRUCTやJSON型を使用する」「横長のテーブルを作成する」という2つの設計方針についても、ディスカッションを行いました。

図4 半構造化データを使用する案
図4は「STRUCTやJSON型を使用する」方針のサンプルです。必要となるページ属性を、すべて1つのカラムにまとめて管理しています。この方針では1つのカラムの中で階層構造を表現できるといった柔軟性の観点でメリットがあります。
先に述べたとおりアクセスログは半構造データを含むことが多いため、ファクトテーブルを作る際にデータ加工の手間を省くことができます。アクセスログに新しい項目が頻繁に追加されるようなフェーズでは、ファクトテーブルにも項目が自動反映されたほうが、メンテナンスの労力は少なくて済むでしょう。ただし、最終的にはデータ分析者が半構造化データを処理することになるのでご注意ください。
この設計方針を採用した場合のデメリットとしては、他ツールとの連携面の弱さが挙げられます。例えば、多くのBIツールではJSON形式のデータをうまく表示できません。BIツールのデータ加工機能を使って前処理を挟む必要が生じます。ディメンショナルモデリングは、データ分析者が「ファクト」と「ディメンション」を組み合わせるだけで、手軽にデータを分析できることがメリットです。そのメリットを損なってしまっては本末転倒です。
データカタログツールでのメタデータ付与も困難になります。メタデータとは、「取りうる値の範囲」や「個人情報に該当するか」など、データを説明するためのデータです。データカタログは「◯◯テーブルのXXカラムにはこういう値が含まれている」といった仕様を利用者に案内するツールです。現状、多くのデータカタログツールでは、カラム単位でメタデータを付与するため、異なる意味を持つデータを1つのカラムに格納した場合、適切にラベリングができなくなってしまいます。
セキュリティ観点のデメリットも無視できません。例えば、商品購入ページに「購入者メールアドレス:xxxxx@example.com」のような項目が含まれているケースを想像してください。個人情報などのセンシティブなデータが含まれていると、データ分析者に閲覧権限を付与できなくなるおそれがあります。「購入者メールアドレス」カラムが独立している場合は、そのカラムだけ無視して、データ分析に必要なカラムに絞って閲覧権限を付与すれば良いでしょう。しかし、複数項目が1つのカラムに含まれてしまうと、その区別ができなくなってしまいます。
同様に、マスキング等によってメールアドレスを匿名化しようとしても、「購入者メールアドレス」カラムを一括で「***」に書き換えるのと、JSONの中からメールアドレスに該当する箇所を探して書き換えるのとでは、前者のほうが開発スピード、保守性、安全性など総合的に優れているように思います。

図5 横長のテーブルを作成する案
対して、図5は「横長のテーブルを作成する」設計方針のサンプルです。ページ属性のカラムをそれぞれ分けています。半構造化データをフラット化して、1つのデータが1つのカラムに含まれるように加工しています。データ分析者がわざわざ加工処理をする必要がなく、すぐにデータ分析を始めることができるようになっています。
直感的には「データを探しにくい」というデメリットを挙げられるでしょう。ページタイプやページ属性が増えるとカラムが増えていき、横に長いテーブルになってしまいます。データ利用者が欲しいカラムを探すのに苦労してしまうかもしれません。
テーブル内に「NULL」が多くなってしまうのも気になる点です。ページタイプに対応しないページ属性のカラムにはNULLが入ります。例えば、「商品閲覧」ページのレコードでは「コンテンツID」が含まれていないため、NULLになっています。第3正規形に慣れ親しんでいるソフトウェア開発者やデータベース管理者にとっては不適切な設計に見えることでしょう。
ディスカッションの結果、「横長のテーブルを作成する」という設計方針を採用するのが良いだろうという結論になりました(図6)。セキュリティ要件に対応しやすい、BIツールやデータカタログと連携できる、データ分析者が前処理・加工せずにデータを利用できるといった点が理由です。データモデリングの目的に立ち戻ると、やはり「データ分析に使えるか」「データ分析に使いやすいか」を重視したいと考えました。
「STRUCTやJSON型を使用する」方針が有効になるのは、データ整備担当者が少ない、SQLの扱いに慣れたデータ分析者が多い、ログの種類が多く仕様が頻繁に変わる、といった場合でしょうか。例えば、研究部門などの組織には向いているかもしれません。普段はデータ分析者たちが各自の判断で半構造化データを加工・処理しつつ、頻繁に参照する項目が明らかになったら、データ整備担当がファクトテーブルを作成するのが良いでしょう。データ分析者が半構造化データを扱いやすいように、サンプルクエリやユーザー定義関数(UDF:よく行う処理や計算を定義したカスタム関数)を社内ポータルサイトで公開している会社もあります。

図6 ページ属性の設計方針まとめ
最後に、ページ属性をディメンションテーブルに分割すべきか検討します。これまでの議論を経て、「fact_サイトアクセス」が、横に長いテーブルになってしまったため「ファクトテーブルに要素を詰め込み過ぎではないか」「ディメンションとして分けるべきではないか」といった意見があがりました。
ディメンショナルモデリングにおいて、「ページ」は本来、What(アクセスする対象物)やWhere(情報の置き場所)にあたる存在だと解釈できます。ページディメンション(dim_ページ)に切り出す設計についても検討する必要があります。また、商品IDやコンテンツIDはページに紐付く情報ではなく、商品ディメンションやコンテンツディメンションに紐づく情報と捉えることもできます。
ディメンションテーブルへの分割について、「ページディメンション(dim_ページ)に切り出す」「スノーフレークスキーマを用いる」「ファクトテーブルで管理する」という3つの設計方針を比較検討しました。
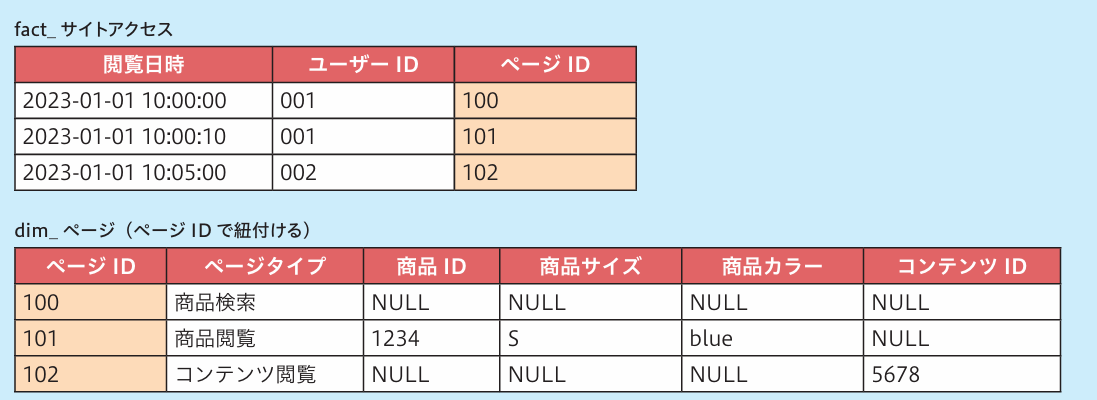
図7 ページタイプやページ属性をディメンションテーブルとする案
ページディメンション(dim_ページ)に切り出す場合(図7)は、「ページを閲覧する」以外にも「ページをSNSでシェアする」「ページを公開・編集する」など複数のビジネスイベントで使用できるテーブルになります。社内でデータ分析が進むほど、専用のディメンションを切り出すことが求められるはずです。
注意点として、ウェブサービスが大量のページを持っている場合、縦長のディメンションテーブル(モンスターディメンション)になり、クエリのパフォーマンスが悪化します。動的ページをグループ化してレコード数を抑えるなどの工夫が必要です。例えば、「会員1人1人のマイページ」(例:「/mypage/senoo」や「/mypage/hamada」)を人数分のレコードとして持つのではなく、「マイページ機能」(例:「/mypage」)を1つのレコードとして管理することで、テーブルのデータ容量を抑えることができます。
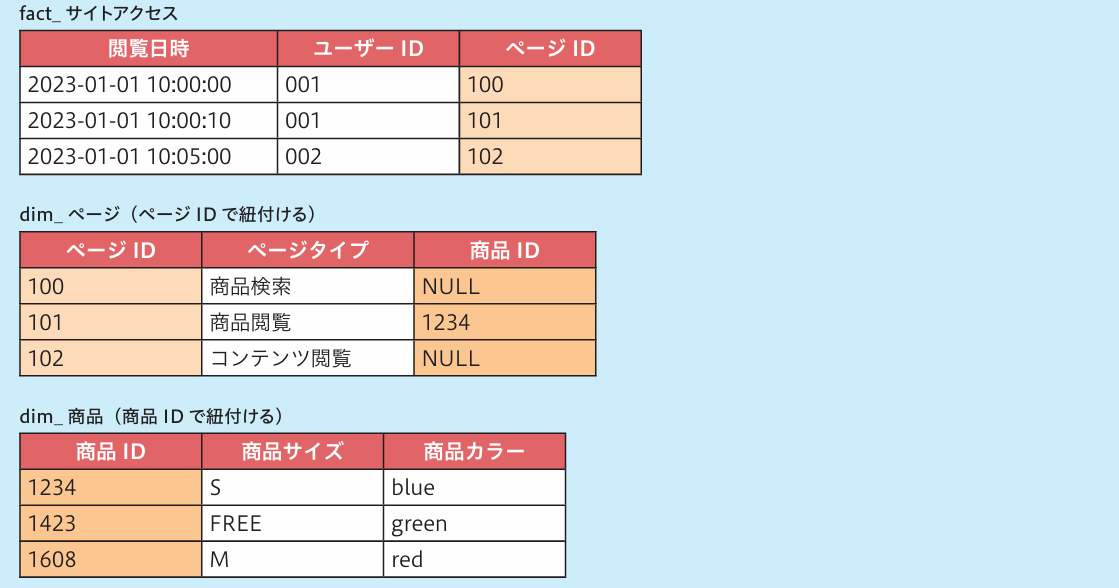
図8 スノーフレークスキーマを用いる案
スノーフレークスキーマを用いる設計方針(図8)では、ページの属性値である「商品ID」を商品ディメンション(dim_商品)と紐付けます。5章で述べられているように、階層を1対多の関係として明示的に定義する必要がある場合は、スノーフレークスキーマを前向きに検討できます。商品ディメンションを別のファクトと結合することも可能です。
一方で、ディスカッションでは以下のデメリットについて懸念する声もあがりました。
- BIツールがスノーフレークスキーマに対応していない。
- データを利用するたびに、テーブル結合の前処理が必要となる。
- dim_ページとdim_商品が履歴値を持つディメンションの場合、カーディナリティが高くなり、件数が増えてしまう。クエリのパフォーマンスが悪化する。
近年はデータウェアハウス製品の高性能化、ストレージコストの低価格化など、データを冗長に持たせやすくなってきたこともあり、シンプルなスタースキーマで十分な場面は増えているように思います。

図9 ページタイプやページ属性をファクトテーブルで管理する案(図21-5と同一内容)
ファクトテーブルで管理する設計方針(図9)では、ファクトテーブルにディメンションの属性を持たせます。この設計を採用する場合、ビジネスイベント発生時の属性をファクトテーブルで管理することになるため、属性の履歴値を取得する際、SQLでの取り扱いが簡単になります。一方でディメンションとして再利用できないテーブルになってしまうというデメリットがあります。
ディスカッションの結果、ページタイプやページ属性は「ファクトテーブルで管理する」のが良いだろうという結論になりました(図10)。今回のケースだと、ページディメンションはユーザーのアクセス分析で使用される以外の用途がまだ見えていない(「適合ディメンション」ではない)ため、ディメンションテーブルとしての汎用性は低いだろうと考えました。
データ活用のフェーズが進み、複数のビジネスイベントで使用できる場合は、ページタイプやページ属性を「ディメンションテーブルで管理する」方式に切り替えることも可能です。その上で、ディメンションに対して1対多の関係になる属性を持つケースにおいては、「スノーフレークスキーマを採用する」ことも検討できます。
初期フェーズでは1つのテーブルで柔軟に対応できる構成にしておき、データ分析者(ユーザー)のニーズの変化に応じて段階的に設計を進化させていくことで、アジャイルなデータモデリングが実現できるのではないでしょうか。もともと「fact_サイトアクセス」案はその思想で採用したため、設計ポリシーを一貫する意図でも「ファクトテーブルで管理する」が妥当のように思えます。
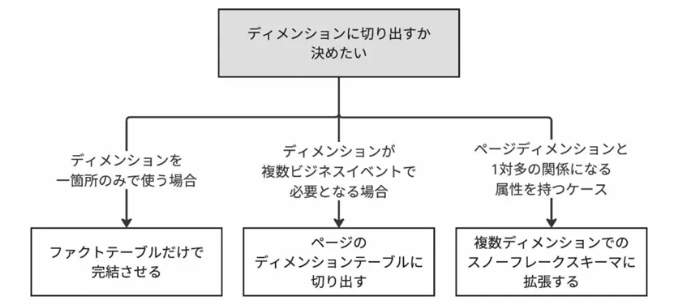
図10 ディメンションの設計方針まとめ
今回議論した3つの論点について、検討した選択肢と採用基準の結論についてまとめます。
論点①:「商品ページにアクセスしたユーザーのリストが欲しい」という要望に対するファクトテーブルはどのように設計すべきか。
- ページアクセスに関するファクトテーブルが存在しない場合は、全ページへのアクセスを格納するファクトテーブルを用意する。
- ページアクセスに関するファクトテーブルがすでに存在し、なおかつパフォーマンスが問題になっている場合は、商品ページへのアクセスに絞ったファクトテーブルを用意する。
論点②:ページ属性をどのように管理するか。
- セキュリティ要件やツール連携面で支障がなく、なおかつデータ分析者が半構造化データを扱える場合は、STRUCT型/JSON型を使用する。
- 上記以外のケースでは、NULLを許容して横長のテーブルを作成する。
論点③:ページディメンションの作成やスノーフレークスキーマの採用を検討すべきか。
- 最初はページ属性をファクトテーブルで管理する。
- データ活用が進み、ページディメンションが複数ビジネスイベントで必要となる場合は、ページディメンションテーブルを切り出す。
- ページディメンションに対して1対多の関係を持つページ属性が存在する場合は、スノーフレークスキーマに拡張する。
今回のディスカッションを経て「データ分析者にとっての使いやすさ(ユーザビリティ)を意識すること」「初期フェーズでの過度なモデリングを避けること」「ユーザーのニーズに応じて段階的に設計を進化させること」など、アジャイルな姿勢こそがデータモデリングにおいて重要だと実感できました。ホワイトボードでの対話から始めて(from Whiteboard)スタースキーマの構築へと(to Star Schema)一歩ずつ進めていくことを徹底していきたいです *1。
*1 本書の原題のサブタイトルは「from Whiteboard to Star Schema」となります。

図11 アジャイルなデータモデリングの実践
ディスカッションから学べることは多く、何よりも純粋に楽しかったです。誰かが「半構造化データのままで管理すればデータを加工しなくて済む」と言ったら、他のメンバーが「データ分析者に負担がよってしまう」と別の視点を提示し、多面的に論点を検討しました。1人で本を読んだだけでは気付けなかったことも多々ありました。
本書でもステークホルダーとのコミュニケーションの重要性が強調されています。データエンジニアの立場だと、「いかに専門的な手法を使いこなすか」という手段にこだわってしまい、「データ分析者に寄り添っているか」という目的を見失いがちです。データエンジニアの思い込みで決めるのではなく、多様な意見を持つ人たちが集まって設計することが必要不可欠だと思います。
本書の翻訳やディスカッションを通してアジャイルなデータモデリングについて学ぶことができました。この学びを実践に活かせるように、風音屋では、データモデリングの議論をするためのSlackチャンネルを作ったり、社内勉強会を開催したりと、データモデリングについてワイワイ話す場所や機会を設けています。
よかったら皆様の組織でも、アジャイルなデータモデリングを実践し、楽しむための工夫をしてみてはいかがでしょうか。周囲の人々がデータモデリング(特にディメンショナルモデリング)を知らないようであれば、ぜひ本書をおすすめしていただければと思います。組織にデータ分析を広めるためのテーブル設計ガイドとして本書をご活用ください。